The Challenge: Strategic Balance in Capture the Flag
Building an agent for the UC Berkeley Pacman Capture the Flag game is a challenging task in multi-agent teamwork. Unlike regular Pac-Man, this version makes agents balance strong offense with solid defense, all while dealing with limited information.
To address this challenge, I created a two-part AI controller that combines Symbolic Planning (PDDL) with Reinforcement Learning (Q-Learning).
The Architecture: A Two-Layered Brain
My agents operate using a “High-Level Thinker, Low-Level Doer” model:
1. High-Level Strategy (PDDL)
We use Planning Domain Definition Language (PDDL) to handle overarching team goals. This layer acts as the strategic general, selecting the best “Mode” for the current game state, such as:
- Attack: Prioritizing food collection when safe.
- Defense: Intercepting intruders on the home side.
- Safe Return: Forcing a retreat once three units of food are collected.
2. Low-Level Execution (Feature-Based Q-Learning)
Once the strategic mode is set, Q-Learning takes over to handle the actual movement. By learning Q-values for specific state-action pairs, the agents fine-tune their paths based on features like:
- Offense: Proximity to the closest food and distance to ghosts.
- Defense: Distance to invaders and maintaining a defensive stance.
The “Kabaddi” Strategy
The main idea behind this project is a semi-defensive approach inspired by Kabaddi.
In this setup, agents mostly stay on their own side to form a strong defense. When they spot a chance, like an enemy getting tagged or a clear path opening up, one agent quickly switches to collecting resources. After a fast raid, the agent returns to the defensive line, scoring points while keeping risk low.
Experimental Results
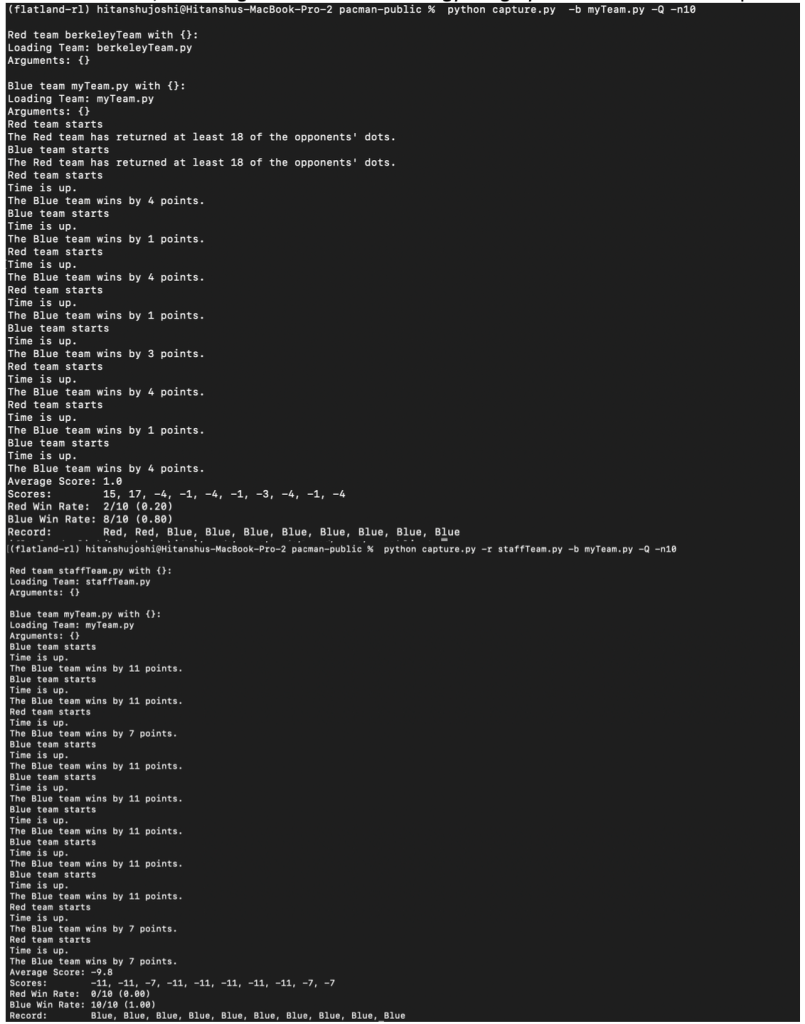
To evaluate the effectiveness of the hybrid model, I conducted 10-round experiments against two distinct opponents:
- Against the Berkeley Team, the agent achieved an 80% win rate with narrow yet consistent margins.
- Against the Staff Team, the agent achieved a 100% win rate, with average score leads of nearly 10 points per game.
If I Were to Do It Now: My Refined Approach
Reflecting on the initial implementation, my approach today would focus on moving from a rigid hybrid system to a fluid, adaptive architecture. If I were to rebuild this controller now, here is how I would evolve the strategy:
1. Transition to Deep Q-Learning (DQL):
While the current feature-based Q-learning is effective, it relies on manually engineered features like “distance to food”. Today, I would implement Deep Q-Learning to let the agents approximate Q-values using a neural network. This would enable them to generalize across complex, unseen map layouts more efficiently than a static table, handling the high-dimensional state space of Pacman with greater precision.
2. Implementing a Shared Q-Network:
To solve coordination issues seen in “Side-Dependence,” I would use a shared Q-network for both agents. By contributing experiences to a single network, the AttackAgent and DefenseAgent would develop compatible policies. This collective learning ensures that if one agent is captured, the other can adapt its role to cover the gap, making the team more resilient to downtime.
3. Dynamic Role Adaptation:
My original “Kabaddi” strategy used fixed roles, which sometimes led to idle downtime. My new approach would eliminate these rigid labels. Instead of a dedicated “DefenseAgent,” I would implement Dynamic Role Switching. The agents would use PDDL to constantly re-evaluate who is best positioned for a “raid” and who should “patrol,” ensuring full engagement throughout the 1200-move limit.

Leave a comment